Watch the presentations!
Both invited and contributed talks have been pre-recorded using SlideLive and are now publicly available here
Workshop Description
The ongoing success of deep learning techniques depends on the quality of the representations automatically discovered from data 1. These representations must capture important underlying structures from the raw input, e.g., intermediate concepts, features, or latent variables that are useful for the downstream task. While supervised learning using large annotated corpora can leverage useful representations, collecting large amounts of annotated examples is costly, time-consuming, and not always feasible. This is particularly problematic for a large variety of applications. In the speech domain, for instance, there are many low-resource languages, where the progress is dramatically slower than in high-resource languages such as English. Moreover, annotations are often underspecified for many potential downstream applications, and the related supervised representations might be biased towards the task they are trained on, limiting their exportability to other applications 2.
Natural ways to mitigate these issues are unsupervised 3 and self-supervised learning 4 5 6 7. Following its increasing popularity within the computer vision community, some attempts have been done to extend self-supervised learning to discover audio and speech representations 8 9 10 11 12 13. Nevertheless, applying self-supervised learning to speech remains particularly challenging. Speech signals, in fact, are not only high-dimensional, long, and variable-length sequences, but also entail a complex hierarchical structure that is difficult to infer without supervision (e.g. phonemes, syllables, words). Moreover, speech is characterized by an important variability due to different speaker identities, accents, recording conditions and noises that highly increase the level of complexity. We believe that self-supervised learning will play a crucial role in the future of artificial intelligence, and we think that great research effort is needed to efficiently take advantage of it in audio and speech applications. With our initiative, we wish to foster more progress on this important topic, and we hope to encourage a discussion amongst experts and practitioners from both academia and industry. Furthermore, we plan to extend the debate to multiple disciplines, encouraging discussions on how insights from other fields (e.g. computer vision and robotics) can be applied to speech, and how findings on speech can be used on other sequence processing tasks. The workshop will be conceived to further promote communication and exchange of ideas between machine learning and speech communities(people who attend conferences such as Interspeech and ICASSP). We really want to encourage scientists from the traditional speech community to contribute more to popular machine learning conferences such as ICML. As a proof of interest from both machine learning and speech communities, our last NeurIPS 2018 workshop on Interpretability and Robustness in Audio, Speech, and Language14 received more than 70 submissions and more than 350 attendees. Encouraged by the success of our past initiative, we would like to raise attention to a very timely and crucial topic. Indeed, self-supervised learning has been the subject of few recent initiatives including the “Beyond Supervised Learning” workshop organized at CVPR 2017 and 201815, and the “Self-Supervised Learning” workshop organized at ICML 2019 16. The key difference lies in our focus on audio and speech technologies, which is a bleeding-edge topic that cannot be fully covered in the main ICML conference.
Call for Papers
We welcome papers on audio and speech that address one or more of the leading topics:
- Self-supervised learning
- Representation and/or feature learning
- Mutual information
- Contrastive losses
- Transfer learning
- Low-resource languages
- Speech augmentation
- Speech enhancement
- Multimodal self-supervised learning
We accept papers up to five pages excluding references and supplementary materials. A few papers will be selected for oral presentations (15 minutes + 5 minutes of questions) while the other accepted papers will be presented in a poster session. Accepted contributions will be made available on the workshop website. Submissions are single-blind and peer-reviewed on OpenReview. To foster transparency and replicability of the published results, we encourage the authors to publicly release the code of their experiments. Each paper will be reviewed by at least three reviewers. Authors and reviewers are asked to disclose any possible conflict of interest. The organizers take the responsibility to properly manage any potential conflict of interest when assigning the submitted manuscripts. Moreover, workshop organizers are excluded from assessing submissions from the same organization.
The accepted papers will be made available on the workshop website. Even though we would prefer original works, double submissions are accepted for relevant papers only. Papers submitted to other conferences or workshops can be thus submitted, but the authors must notify it to the organizers (with an email to sas@googlegroups.com). Preprint papers already published on ArXiv, ResearchGate, Academia or similar repositories can be submitted as well. Even though official proceeding will not be released, the accepted papers will be made available into the workshop website. Double-submitted papers will be published into the website only if no conflicts with other conferences arise.
Please note that it will not be feasible to submit a new paper after the Abstract Deadline (June 10th).
Submission Guidelines
All submissions must be in PDF format. Submissions are single-blind and limited to five content pages including all figures and tables but excluding references and supplementary materials. Submissions must follow the official ICML guidelines. The camera-ready papers must use the workshop style file.
- Download the ICML template here
- Go to our OpenReview website to submit your work. Please note that you must be registered to OpenReview first.
Camera-ready papers will be due in advance of the workshop. Final acceptance of a submission will be conditioned on providing a camera-ready version of the paper that fits our formatting instructions. Papers that are over length or violate the author guidelines format will be rejected without review.
Important Dates
- Paper deadline: June 15th (00:00 anywhere on earth)
- Notifications: July 1st
- Workshop date: July 17th
Invited Speakers
- Karen Livescu, Toyota Technological Institute at Chicago, (USA).
Title: Unsupervised pre-training of bidirectional speech encoders via masked reconstruction.
- Aäron van den Oord, Google DeepMind London, (UK).
Title: Contrastive Predictive Coding for audio representation learning.
- Jan Chorowski, University of Wrocław, (PL).
Title: Representation learning on sequential data with latent priors.
- Kristen Grauman, University of Texas at Austin, (USA).
Title: Sights and sounds in 3D spaces.
- Lorenzo Torresani, Facebook AI, (USA).
Title: Self-Supervised Video Models from Sound and Speech.
- Aapo Hyvärinen, University of Helsinki, (FI).
Title: Denoising and real-vs-corrupted classification as two fundamental paradigms in self-supervised learning.
- Alexei Baevski, Facebook AI, (USA).
Title: Self-supervised learning of speech representations with wav2vec.
Accepted Papers
-
End-to-End ASR: from Supervised to Semi-Supervised Learning with Modern Architectures
Gabriel Synnaeve, Qiantong Xu, Jacob Kahn, Tatiana Likhomanenko, Edouard Grave, Vineel Pratap, Anuroop Sriram, Vitaliy Liptchinsky, Ronan Collobert -
Learning Speech Representations from Raw Audio by Joint Audiovisual Self-Supervision
Abhinav Shukla, Stavros Petridis, Maja Pantic* -
COALA: Co-Aligned Autoencoders for Learning Semantically Enriched Audio Representations
Xavier Favory, Konstantinos Drossos, Tuomas Virtanen, Xavier Serra -
Adversarial representation learning for private speech generation
David Ericsson, Adam Östberg, Edvin Listo Zec, John Martinsson, Olof Mogren -
Analysis of Predictive Coding Models for Phonemic Representation Learning in Small Datasets
María Andrea Cruz Blandón, Okko Räsänen -
OtoWorld: Towards Learning to Separate by Learning to Move
Omkar Ranadive, Grant Gasser, David Terpay, Prem Seetharaman -
Language Agnostic Speech Embeddings for Emotion Classification
Apoorv Nandan, Jithendra Vepa -
Bootstrapping Unsupervised Deep Music Separation from Primitive Auditory Grouping Principles
Prem Seetharaman, Gordon Wichern, Jonathan Le Roux, Bryan Pardo -
Self-supervised Pitch Detection by Inverse Audio Synthesis
Jesse Engel, Rigel Swavely, Lamtharn Hanoi Hantrakul, Adam Roberts, Curtis Hawthorne -
Unsupervised Speech Separation Using Mixtures of Mixtures
Scott Wisdom, Efthymios Tzinis, Hakan Erdogan, Ron J Weiss, Kevin Wilson, John R. Hershey -
Investigating Self-supervised Pre-training for End-to-end Speech Translation
Ha Nguyen, Fethi Bougares, Natalia Tomashenko, Yannick Estève, laurent besacier -
Using Self-Supervised Learning of Birdsong for Downstream Industrial Audio Classification
Patty Ryan, Sean Takafuji, Chenhao Yang, Nile Wilson, Christopher McBride -
Understanding Self-Attention of Self-Supervised Audio Transformers
Shu-wen Yang, Andy T. Liu, Hung-yi Lee
Schedule
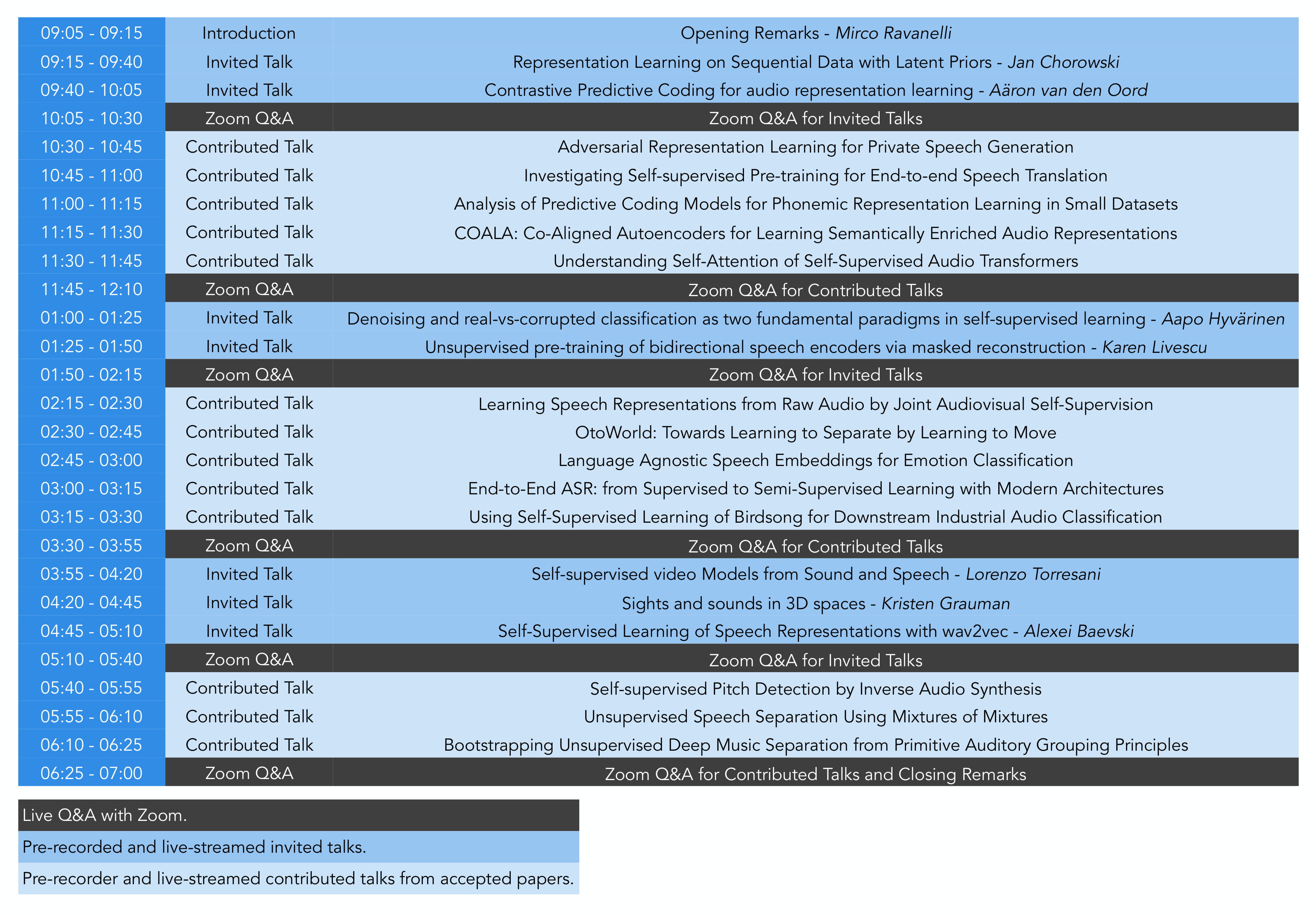
The workshop will be entirely streamed with SlideLive. In practice, three blocks composed of invited and contributed talks will be streamed through the day. Two live Q&A Zoom sessions are included within each block. The first one starts at the end of the invited talks, while the second one takes place after the contributed talks. A chair will ensure that all the speakers get the same amount of time if too much questions are asked. Timezone is CET
Organization committee
- Mirco Ravanelli:

Mirco is currently a post-doc researcher at MILA (Université de Montréal) working under the supervision of Prof. Yoshua Bengio. His main research interests are deep learning, speech recognition, far-field speech recognition, robust acoustic scene analysis, cooperative learning, and unsupervised learning. He is the author or co-author of more than 40 papers on these research topics. He received his PhD (with cum laude distinction) from the University of Trento in December 2017. During his PhD, he focused on deep learning for distant speech recognition, with a particular emphasis on noise-robust deep neural architectures. He is an active member of the speech and machine learning communities. He co-organized the IRASL@NeurIPS 2018 workshop on Interpretability and robustness in audio and speech. In the last few years, he co-organized several special sessions within the major speech conferences (e.g, ICASSP, Interspeech and Eusipco). He also co-organized a research team working on cooperative approaches for speech recognition in the context of the 2019 Sixth Frederick Jelinek Memorial Summer Workshop.
- Dmitriy Serdyuk:

Dmitriy is a senior PhD student at the University of Montreal, Mila - Quebec Institute for Artificial Intelligence. His research interests include end-to-end speech recognition systems, spoken language understanding, and sequential generative models. Dmitriy has experience organizing scientific meetings. He was one of the co-organizers of the IRASL workshop at NeurIPS 2018, his responsibilities included the management of the review process, inviting speakers, and the workshop dissemination. Furthermore, Dmitriy was one of the organizers for a special session at IEEE ACSSC Asilomar conference where he was in charge of dissemination and peer review.
- Titouan Parcollet:

Titouan is a senior research associate at the University of Oxford (UK) within the Oxford machine learning systems group. He received his PhD in computer science from the University of Avignon (France) and in partnership with Orkis focusing on quaternion neural networks, automatic speech recognition, and representation learning. He is also currently collaborating with the university of Montréal (Mila, QC, Canada) on the SpeechBrain project. His current research interests are focused on efficient speech processing including self-supervised learning and new artificial neuron representations.
- Devon Hjelm:

Devon is a Senior Researcher at Microsoft Research, an adjunct professor at the University of Montreal, and an associate member at Mila. He earned his PhD at the University of New Mexico with the Mind Research network, where he focused on representation learning of neuroimaging data. He then did a postdoc under Yoshua Bengio at Mila, where he focused on adversarial learning. His key works involve mutual information estimation using neural networks (MINE) and representation learning using self-supervision and mutual information objectives (Deep InfoMax). His current focus is on how to use interactions with mutual information objectives and self-supervision to learn more useful representations that generalize to a wide range of downstream tasks.
- Bhuvana Ramabhadran:

Bhuvana (IEEE Fellow, 2017, ISCA Fellow 2017) currently leads a team of researchers at Google (Senior Staff Research Scientist), focusing on multilingual speech recognition and synthesis. Previously, she was a Distinguished Research Staff Member and Manager in IBM Research AI, at the IBM T. J. Watson Research Center, Yorktown Heights, NY, USA, where she led a team of researchers in the Speech Technologies Group and coordinated activities across IBM’s world wide laboratories in the areas of speech recognition, synthesis, and spoken term detection. She was the elected Chair of the IEEE SLTC (2014–2016), Area Chair for ICASSP (2011–2018) and Interspeech (2012–2016), was on the editorial board of the IEEE Transactions on Audio, Speech, and Language Processing (2011–2015), and is currently an ISCA board member. She is a Fellow of ISCA and an adjunct professor at Columbia University. She has published over 150 papers and been granted over 40 U.S. patents. Her research interests include speech recognition and synthesis algorithms, statistical modeling, signal processing, and machine learning. Some of her recent work has focused on understanding neural networks and finding alternate models that can beat or perform as well as deep networks.
Contacts
For any question, feel free to contact us at icml-sas@googlegroups.com
References
-
Yoshua Bengio. Deep learning of representations for unsupervised and transfer learning, 2012 ↩
-
Michael T. Rosenstein, Zvika Marx, Leslie Pack Kaelbling. To Transfer or Not To Transfer, 2005 ↩
-
Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle. Greedy Layer-Wise Training of Deep Networks, 2007 ↩
-
Carl Doersch, Andrew Zisserman†. Multi-task Self-Supervised Visual Learning, 2017 ↩
-
Spyros Gidaris, Praveer Singh, Nikos Komodakis. Unsupervised representation learning by predicting image rotations, 2018 ↩
-
Ishan Misra, C. Lawrence Zitnick, Martial Hebert1. Shuffle and Learn: Unsupervised Learning using Temporal Order Verification, 2016 ↩
-
R. Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Backman, Adam Trischler, Yoshua Bengio. Learning deep representations by mutual information estimation and maximization, 2019 ↩
-
Aren Jansen, Manoj Plakal, Ratheet Pandya, Daniel P. W. Ellis, Shawn Hershey, Jiayang Liu, R. Channing Moore, Rif A. Saurous. Unsupervised learning of semantic audio representations, 2018 ↩
-
Jan Chorowski , Ron J. Weiss , Samy Bengio, Aäron van den Oord. Unsupervised speech representation learning using wavenet autoencoders, 2019 ↩
-
Aaron van den Oord, Yazhe Li, Oriol Vinyals. Representation learning with contrastive predictive coding, 2018 ↩
-
Mirco Ravanelli, Yoshua Bengio. Learning speaker representations with mutual information, 2018 ↩
-
Santiago Pascual, Mirco Ravanelli, Joan Serrà, Antonio Bonafonte, Yoshua Bengio. Learning problem-agnostic speech representations from multiple self-supervised tasks, 2019 ↩
-
Mirco Ravanelli, Jianyuan Zhong, Santiago Pascual, Pawel Swietojanski, Joao Monteiro, Jan Trmal, Yoshua Bengio. Multi-task self-supervised learning for Robust Speech Recognition, 2019 ↩
-
NeurIPS 2018 workshop on Interpretability and Robustness in Audio, Speech, and Language ↩